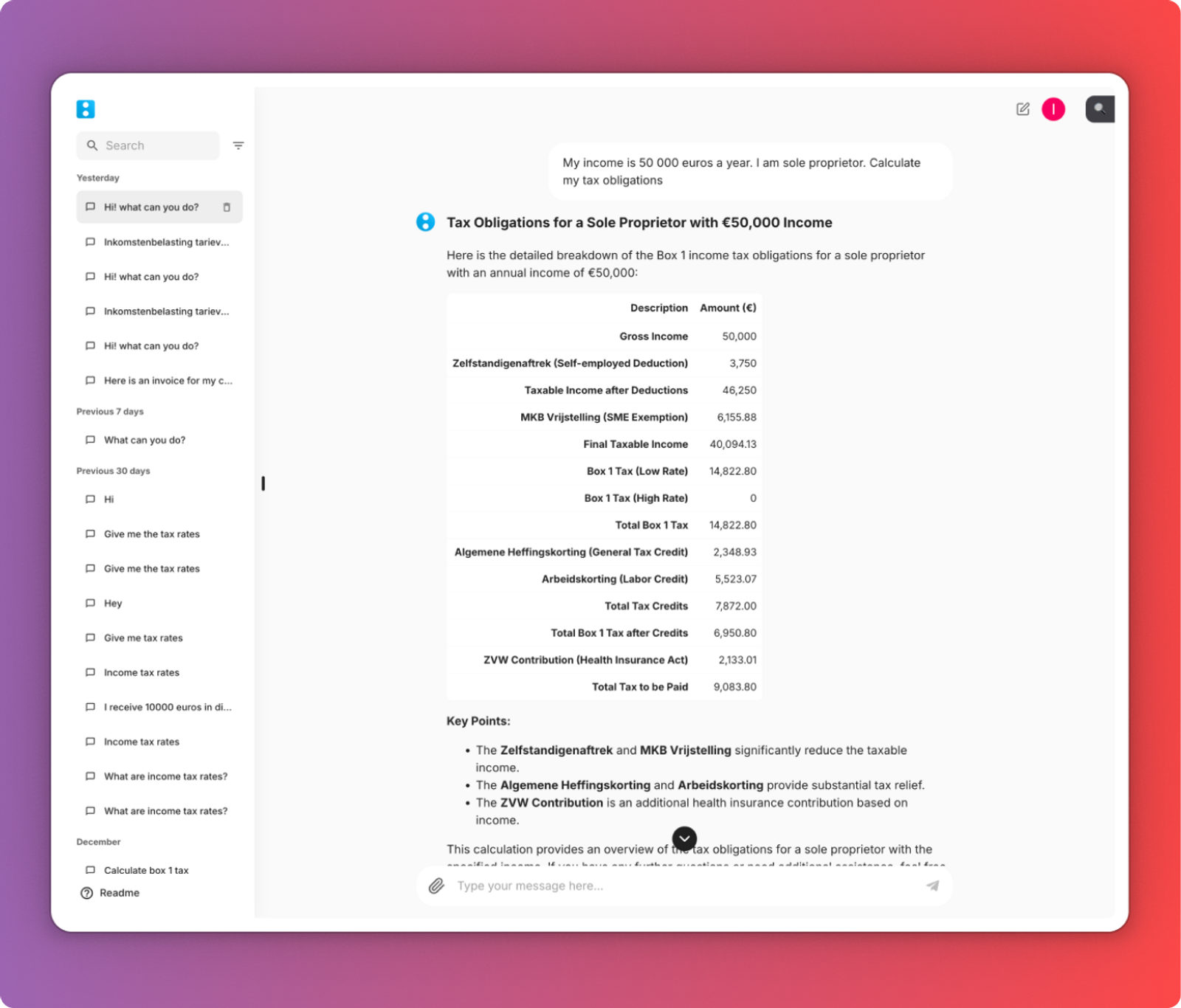
Our team has developed an AI-powered tax assistant that specializes in the Netherlands law. The assistant is able to read and analyze text documents in practically any popular format (PDF, PNG, Docx, Excel, etc.), perform various tax calculations for specific scenarios, and provide the user with links to corresponding laws and legal cases on the basis of which it prepared a response.
For example, a customer of the service can upload an invoice for a car purchase and ask the assistant to calculate fiscal obligations for the purchased vehicle and how they would differ if the car was being used for personal or commercial use. The bot will provide instant tax assistance, and answer any scenario-specific tax-related questions. The tax AI specialist will analyze your documents and search the knowledge database to provide you with answers supported by recent laws and legal cases. This retrieval-augmented generation (RAG) process is often implemented when developing AI-driven solutions that rely on industry-specific knowledge.
Solution development:
Our team conducted a thorough discovery phase where we used a data-driven approach, with many variables that were rigorously tested and measured to choose the best architecture and the most fitting models for this project. At the end of our research, our team presented a detailed Software Requirement Document (SRD), as well as an in depth Research Notes document depicting our findings and a clear action plan.

We built the frontend UI of the bot web application with React. The AI assistant had to be able to give consultations on the legislature of the Netherlands, make calculations, and search for legal cases similar to the user search query. To make our AI tax expert consultations reliable we used three main resources of information:
- Legal industry knowledge;
- Information bank of law cases (ECLI);
- An online resource with articles on the laws of the Netherlands - where each article is written in simple, human language that lets us augment the dry legislative language of laws and legal cases.
There are about 48362 ECLI (legal) cases, 606 laws, and 795 law articles currently in the database, and these numbers are only inclined to grow. In our projects, we widely employ tool use (function calling), deterministic approaches, and LLM approaches which make the systems we build secure and efficient.
The tax assistant web app also has a semantic search for legal cases. The challenge with this search implementation was in the format of the cases, as they are very bulk. The solution lay in making a case summary first and then conducting the search based on that summary instead of the whole document which improved the search results quite a bit.
Another minor challenge we faced was the training data language, even though Dutch is a part of the Germanic language group, there were some issues surrounding this process.
An important part of the assistant's architecture was its traceability, so its thought process and information sources could be checked to see how well it worked. For the assistant's thought process to be traceable our team has included such traceability instruments as threads that show what information the assistant used, how his thoughts were formed, and understand the logic by which the answers were constructed.
Agentic RAG is another architecture we used that lets the bot work in a cycle of: Thought-Action-Action-Input-Pause-Observation-Answer. We have also used Langfuse to analyze the assistant's thought process, it shows the thoughts of an agent through functions. Even though it's a lower-level tracer it's more universal and customizable.
To improve the accuracy and quality of queries sent to the database in search of an answer we used prompt engineering techniques and a mix of hybrid search and re-ranking. For re-ranking, we used Cohere which helps rank the documents being pulled from DB by closeness to the query. This process makes the list of the cited resources consist of the most crucial documents. We have also further improved the search by using different chunking strategies. As we worked with data we realized that it would be beneficial to switch from LangChain to custom Python code so that we can be more precise and make the architecture easier to adapt to our needs.
Data orchestrators help optimize and automate the data gathering, processing, and integration into the database. In this project, we implemented an effective data orchestration instrument that helps manage the workflow, set up a data pipeline, and even do it on schedule at a previously set time. For example, we scheduled our data orchestrator to look for new laws each year when they are renewed, scrape them, break them down into parts, process the information, and save it in our DB - a process known as ETL (extract, transform, and load).
Because the model is specialized in a certain field it’s quite challenging to use the standard metrics for its evaluation. To properly evaluate the performance of our model we are forming a dataset that consists of queries and answers, so we could numerically evaluate the responses taking into account such characteristics as accuracy, and context precision of the answer.
The outcome
The AI tax assistant, trained on Netherlands tax and legal regulations, can help clients navigate complex tax matters and provide legal guidance, reducing errors and saving time. This project demonstrates how AI can simplify legal complexities while delivering reliable support for individuals and businesses.
The assistant has helped our client greatly in his everyday work, improved efficiency, and saved valuable time. Our client compares the assistant to the "Volkswagen" of the AI world, secure, reliable, and efficient. In the future, our client is hoping to make this tool available for public use.
Technologies used:

Cohere
Cohere is an AI platform that provides powerful natural language processing (NLP) models through an API. It specializes in large-scale language models for tasks like text generation, summarization, translation, and question-answering.

Hatchet
Hatchet is a distributed, fault-tolerant task queue which replaces traditional message brokers and pub/sub systems - built to solve problems like concurrency, fairness, and durability.

Langfuse
An open-source observability tool for LLM applications. It enables developers to track, log, and analyze model interactions, improving performance, debugging, and monitoring across complex AI workflows.

OpenAI
OpenAI provides models like GPT (Generative Pre-trained Transformer), which excels in natural language understanding and generation. These models can be used to build everything from chatbots and content generators to code assistants and data analyzers. OpenAI's API is incredibly versatile, allowing easy integration into web and mobile applications.

AWS
Whether you're looking for compute power, database storage, content delivery, or other functionality, AWS has the services to help you build sophisticated applications with increased flexibility, scalability and reliability

Python
Python is an interpreted, object-oriented, high-level programming language with dynamic semantics.

Weaviate
An open-source vector database that enables efficient storage, search, and retrieval of high-dimensional data. It powers AI applications by offering fast semantic search, natural language processing, and integration with large language models (LLMs) for managing unstructured data.

React.js
The library for web and native user interfaces. Whether you work on your own or with thousands of other developers, using React feels the same. It is designed to let you seamlessly combine components written by independent people, teams, and organizations.












