What is RAG?
In our previous article, we explored RAG in AI. Let’s briefly recap what retrieval-augmented generation is all about.
Large Language Models (LLMs), such as OpenAI's GPT series, Meta's LLama series, and Google's Gemini, have made remarkable progress in the field of generative AI. However, these models can sometimes generate responses that are incorrect (a phenomenon called hallucination), rely on outdated data, and operate in a way that lacks transparency. The retrieval-augmented generation framework addresses these issues by enriching LLMs with additional information. RAG is widely used in modern question-answering applications such as chatbots, but its applications extend far beyond question-answering and conversational bots to include document summarization, enterprise search, personalized recommender systems, and more.
Technological progress doesn't stand in one place, and RAG is changing with time, too. Let's explore how RAG systems evolved over the last few years and discover the differences between Naive RAG, Advanced RAG, and Modular RAG frameworks.
RAG: naive, advanced & modular
The RAG framework is constantly advancing and has three main types of architecture: Naive RAG, Advanced RAG, and Modular RAG. While the RAG approach is both cost-efficient and outperforms the native LLM in many aspects, it still has certain limitations. Advanced RAG and Modular RAG aim to address the specific weaknesses found in Naive RAG.
Naive RAG is the most uncomplicated version, in which the system retrieves the relevant information from a knowledge base and directly gives it to the LLM to generate the response.
Advanced RAG goes a step further by adding extra processing steps before and after retrieval to refine the retrieved information to enhance the accuracy of the generated response.
Modular RAG is the most complex yet accurate approach. It remains rooted in the core principles of Advanced and Naive RAG and offers unique features such as adding a search module for similarity queries and fine-tuning the retriever. In this architecture, new approaches, like the reorganization of RAG modules and restructured RAG pipelines, have been introduced to address specific challenges.
RAG has gained attention as an effective solution that improves the accuracy of AI-generated content, especially for tasks requiring extensive knowledge, continuous updates, and the inclusion of domain-specific data. The RAG framework is evolving to address drawbacks, such as challenges in retrieval and generation. Advanced RAG and Modular RAG were developed to overcome these limitations.
Naive RAG
Naive RAG represents a system that retrieves relevant information from a knowledge base and passes it directly to the LLM for output generation. Following a straightforward process, Naive RAG consists of four main steps: indexing, retrieval, augmentation, and generation.
Indexing involves preparing and organizing raw data from various formats, such as PDFs, HTML files, Word documents, and Markdown. In this step, the data is cleaned, extracted, and converted into a uniform plain-text format.
More specifically, data indexing involves such processes as:
- Data loading involves importing all the documents or information that will be used.
- Data splitting is a process that breaks large documents down into smaller segments, such as chunks of up to 500 characters each.
- Data embedding is transforming content into vector representations using an embedding model, making it machine-readable.
- Data storing lets vector embeddings be stored in a vector database, enabling efficient search and retrieval.
Retrieval begins when a user submits a query. The system encodes the query into a vector representation (query vector) using the same embedding model employed during indexing. Then, the similarity scores between the query vector and the vectors of text chunks in the indexed database are calculated. And finally, the system identifies and retrieves the top K chunks with the highest similarity to the query.
Augmentation combines the user's query with the relevant retrieved data. These chunks are then added as context to the prompt.
Generation uses the retrieved and augmented context to produce a response tailored to the user's query.
Advantages of Naive RAG:
- Naive RAG is easy to deploy as it combines retrieval and generation, simplifying the process of enhancing language models without requiring complex modifications or additional elements.
- A major benefit of Naive RAG is that there is no need to fine-tune the LLM, which saves time and reduces costs.
- Naive RAG significantly enhances the accuracy of its outputs By using external and up-to-date information.
- RAG addresses the common problem of LLMs producing fabricated information called hallucinations by grounding responses in factual data retrieved during the process.
Challenges:
- Limited processing when the retrieved data is used as-is, without further adjustment, can result in inconsistencies in the generated content.
- The effectiveness of the output is heavily influenced by the retrieval module's ability to locate the most relevant information.
- Naive RAG may have difficulty grasping the broader context of a query, producing responses that, while accurate, might not completely align with the user's intent.

Advanced RAG
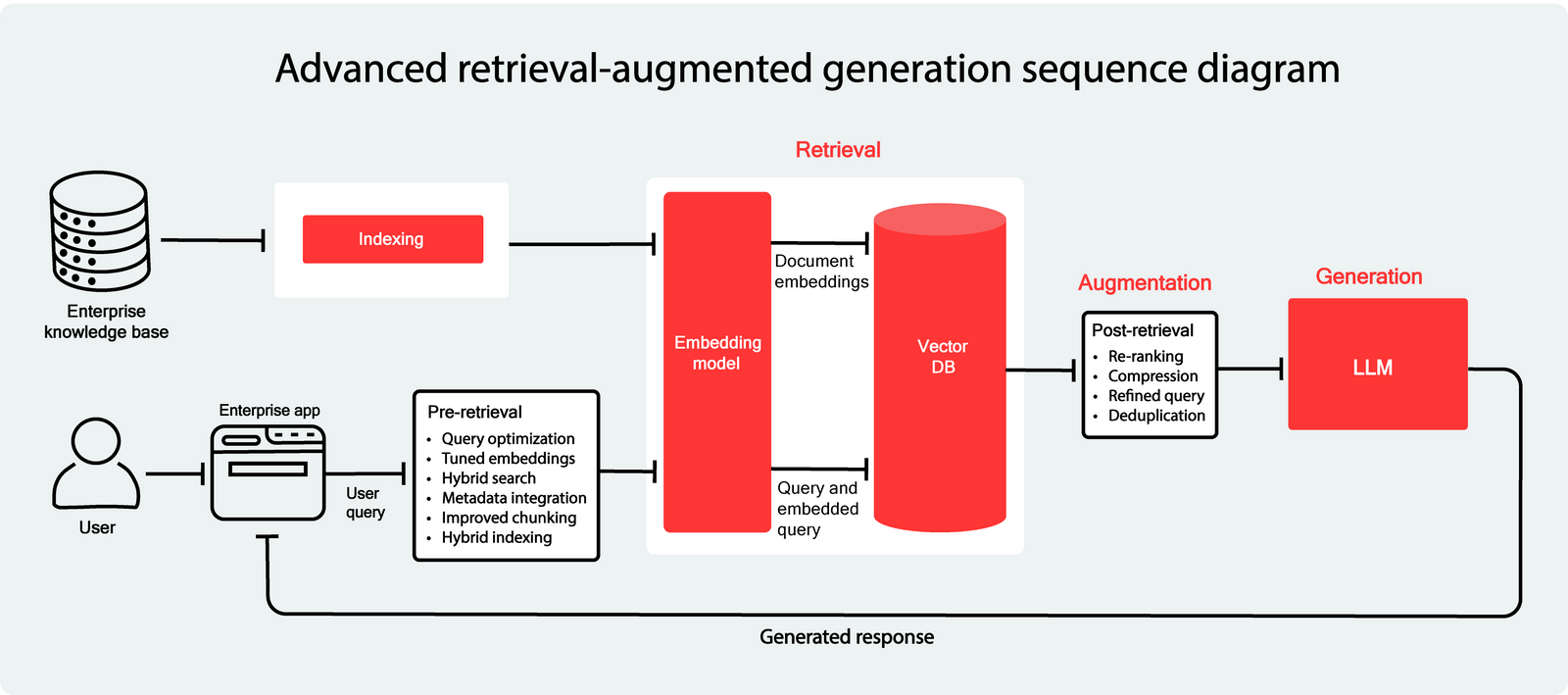
Expanding on the principles of Naive RAG, Advanced RAG adds a layer of refinement to the process. Instead of simply using retrieved information as-is, Advanced RAG incorporates extra processing steps to enhance the relevance and improve the overall quality of the responses. These extra steps are called pre-retrieval and post-retrieval.
Pre-retrieval
In Advanced RAG, the retrieval process is optimized even before it begins. Let’s explore what kind of optimizations the pre-retrieval phase involves:
1. Improved data chunking
The sliding window method takes advantage of overlaps between chunks, capturing context across boundaries and improving the coherence of retrieved chunks. Another useful data chunking method is adaptive chunking which dynamically adjusts chunk sizes based on content complexity or query requirements which results in a more meaningful division of data.
2. Dynamic and specialized embeddings
Domain-specific fine-tuning lets embedding models be fine-tuned with domain-specific datasets, allowing the system to capture nuanced information relevant to specialized tasks. Iterative embedding refinement can also improve relevance, and it involves periodic updates and retraining of embeddings, aligning them with evolving datasets and queries.
3. Hybrid indexing techniques
Advanced RAG uses a mix of indexing algorithms to combine the strengths of different approaches.
- Graph indexing represents entities and their relationships as nodes and edges, improving the system's ability to retrieve contextually rich and connected information.
- Hierarchical indexing organizes data in a layered manner, providing efficient navigation through large datasets for both general and specific queries.
- Vector indexing uses embeddings to represent data in a high-dimensional space, allowing semantic searches based on similarity.
- MSTG (Multi-Strategy Tree-Graph) indexing combines hierarchical tree and graph structures to optimize for both filtered and unfiltered searches for fast and accurate retrieval. This hybrid approach balances the strengths of both methodologies for varied search requirements.
- Advanced RAG supports incremental indexing, which allows the system to update the index with new data without needing a complete rebuild, allowing the system to remain up-to-date with the latest information.
4. Metadata integration
Including metadata in the indexing process can improve filtering and retrieval capabilities. Metadata fields like document type, source, creation date, or relevance scores help refine searches and help the system retrieve contextually appropriate chunks.
5. Query refinement
Before the retrieval phase begins, user queries are enriched to improve their precision. Techniques like query rewriting, expansion, and transformation are applied in this step so the system retrieves the most appropriate information. For instance, a vague query can be refined by adding context or specific keywords, while query expansion introduces synonyms or related terms to capture a broader range of relevant documents.
6. Hybrid search
A hybrid search approach enhances retrieval capabilities by combining various search techniques, such as keyword-based, semantic, and neural searches. For example, MyScaleDB supports both filtered vector and full-text searches while, thanks to its SQL-friendly syntax, allowing the use of complex SQL queries. This hybrid strategy presents highly relevant results, regardless of the query type or complexity.
Retrieval
In this step of Advanced RAG, we can improve our processes by optimizing chunk embedding and retrieval. After determining the chunk size, the next step is embedding these chunks into a semantic space with the help of an embedding model.
Optimizing chunk retrieval
During retrieval, the most relevant parts are identified by measuring how similar the query and the embedded chunks are. Embedding models can be fine-tuned to improve this process. For an embedding model to have the best chance to capture the nuances of domain-specific information, fine-tuning with customized datasets has to be performed. These custom datasets should include: queries related to the domain, a body of domain-relevant content, and documents that provide contextually accurate information.
Choosing similarity metrics
Selecting the right similarity metric is critical for optimizing retrieval accuracy. Many vector databases, such as ChromaDB, Pinecone, and Weaviate, support a variety of similarity metrics. Examples include:
- Cosine similarity calculates the cosine of the angle between two given vectors and is useful for high-dimensional data when it is important to capture semantic similarity;
- Euclidean distance (L2) measures the straight-line distance between two points and is more likely to be used for lower-dimensional data;
- Dot product evaluates the scalar product of two vectors and is used in scenarios where the magnitude of vectors is relevant to the computation;
- L2 squared distance, which involves squaring the Euclidean distance, is most commonly used in scenarios where the magnitude of differences between points is critical, and you want to penalize large deviations more than small ones;
- Manhattan distance measures the distance between points based on a grid-like path and is particularly useful in scenarios where differences between attributes are measured as the absolute sum of their deviations along each dimension.
Fine-tuning embedding models with domain-specific data and optimizing similarity metrics allows RAG to retrieve more accurate information.
Post-retrieval
Once the context data (chunks) is retrieved from a vector database, the next step is combining it with the user’s query to create input for the language model. However, these chunks can sometimes include duplicate, noisy, or irrelevant information, potentially affecting how the LLM interprets and processes the context. Below are some strategies to address these challenges effectively:
1. Re-ranking for prioritization
Advanced RAG introduces re-ranking as an additional step after retrieval to refine the information so that the most relevant and valuable data is given priority.
Initially, the system retrieves multiple chunks related to the query, but not all of them hold equal importance. Re-ranking reassesses this information using such factors as:
- Semantic relevance that determines how closely the data aligns with the query.
- Contextual fit provides information on how well the data integrates into the broader context.
By reorganizing the retrieved chunks, re-ranking pushes the most pertinent information to the top.
2. Contextual compression
To further improve the precision and clarity of the generated response contextual compression focuses only on what's crucial to answer the query and eliminates any extra noise. While contextual compression enhances conciseness and precision of the context, care must be taken to retain information critical for accurate responses.
3. Query refinement
A feedback loop improves the understanding of the user query. Dynamic query adjustment, based on the retrieved results, refines the query to better target relevant chunks. The refined query can also trigger another round of retrieval to fetch additional or more accurate information, a process referred to as iterative retrieval.
4. Deduplication and conflict resolution
When multiple chunks contain overlapping or contradictory information, such processes as deduplication identify and remove duplicate chunks, and conflict handling prioritizes the most reliable sources or combines data intelligently to resolve inconsistencies.
Advantages of Advanced RAG:
Advanced RAG offers improvements that enhance the quality and effectiveness of language model outputs compared to Naive RAG:
Improved relevance with re-ranking that prioritizes the most relevant information, providing more accurate and coherent responses.
Task-specific context with dynamic embeddings allows the system to better understand and respond to different queries by tailoring context to specific tasks.
Enhanced accuracy through hybrid search that combines multiple search strategies, and retrieves data more effectively.
Streamlined responses due to context compression, which removes unnecessary details and speeds up the process, providing more concise, high-quality answers.
A deeper understanding of user queries with techniques like query rewriting and expansion.
Advanced RAG represents a significant step forward by introducing additional refinement stages and addresses the limitations of Naive RAG.
Modular RAG
Modular RAG builds on the foundation laid by Advanced RAG, integrating specialized modules and techniques to create a more adaptable RAG system. Key innovations in modular RAG include such processes as:
Enhanced System Architecture
Modular RAG introduces restructured components and rearranged pipelines to address specific challenges in traditional RAG setups. While it represents a leap in complexity and capability, it remains grounded in the core principles of Advanced and Naive RAG and presents a refined evolution within the RAG family.
New modules for improved functionality
- Search module
Designed for targeted searches, this module allows retrieval from diverse data sources, such as databases, search engines, and knowledge graphs. Leveraging LLM-generated code and query languages enhances the retrieval process for specific scenarios.
- RAG-fusion
This process overcomes traditional search limitations through multi-query strategies. It broadens user queries into multiple perspectives, performs parallel vector searches, and uses intelligent re-ranking to uncover hidden knowledge.
- Memory module
Uses the LLM’s memory to guide retrieval. By iteratively refining the context, it creates an evolving memory pool, aligning data more closely with text distribution for improved relevance.
- Routing module
Directs queries through the most appropriate pathways based on their requirements, whether it's summarization, database searches, or merging data streams.
- Predict module
Generates relevant context directly from the LLM to reduce redundancy and noise, improving the precision and accuracy of results.
- Task adapter module
Customizes the system for specific downstream tasks. It automates prompt generation for zero-shot queries and creates task-specific retrievers for few-shot learning scenarios, improving task-specific adaptability.
New patterns for flexibility and scalability
Modular RAG is highly adaptable, with seamless substitution or reconfiguration of modules to address specific challenges. Unlike the fixed "Retrieve and read" mechanisms of Naive and Advanced RAG, Modular RAG supports flexible interaction flows and integrates new components as needed. Modular RAG represents a significant advancement in the retrieval-augmented generation addressing limitations in earlier RAG paradigms while expanding its potential across diverse applications. This evolution solidifies Modular RAG as the standard for building cutting-edge RAG systems.
Choosing the right architecture for projects
Aspect | Naive RAG | Advanced RAG | Modular RAG |
|---|---|---|---|
Complexity | Simple architecture with minimal components and direct integration of retrieval and generation. | Adds additional layers of processing, such as query refinement, re-ranking, and context compression. | Highly flexible and adaptable with modular components, allowing for advanced techniques like memory modules, search modules, and task-specific customizations. |
Performance | Limited performance relies heavily on retrieval quality without post-retrieval enhancements. | Improved performance through re-ranking, hybrid search, and contextual refinement. | Best performance due to specialized modules for specific tasks, including multi-query strategies and fusion techniques. |
Relevance | Basic retrieval - lacks refinement in terms of relevance or coherence. | Significantly better relevance through dynamic embeddings, query rewriting, and re-ranking. | Exceptional relevance, with custom modules for domain adaptation, fine-tuned embeddings, and advanced routing strategies. |
Flexibility | Rigid structure - not easily adaptable to domain-specific requirements. | More flexible than Naive RAG, with improved adaptability for general tasks. | Highly flexible - modular design supports easy reconfiguration, module substitution, and addition of new components for diverse use cases. |
Scalability | Limited scalability due to inefficiencies in retrieval and generation as the dataset grows. | Better scalability with hybrid search and context compression. | Highly scalable, it's modular architecture makes efficient handling of large datasets and complex queries through specialized modules. |
Best use cases | Simple projects requiring minimal setup and straightforward retrieval. | Projects needing more accurate and contextually relevant responses with moderate complexity. | Complex, large-scale projects with domain-specific requirements and a need for high customization, efficiency, and adaptability. |
Naive RAG
Best for: Small-scale projects or prototypes with basic requirements where implementation speed and simplicity are the primary concerns.
Example use cases: Quick information retrieval systems for FAQs or small datasets and lightweight applications with limited computational resources.
Advanced RAG
Best for: Projects requiring moderate levels of accuracy and context relevance, as well as tasks where retrieval refinement, query enhancement, and improved coherence are needed.
Example use cases: Customer support chatbots requiring nuanced answers or educational tools needing contextual refinement for knowledge delivery.
Modular RAG
Best for: Complex, domain-specific applications that demand advanced customizations and high efficiency and projects requiring scalability, multiple data source integrations, and tailored task handling.
Example use cases: Enterprise-level knowledge management systems or legal, healthcare, or financial applications requiring detailed domain adaptation, as well as research and development tools handling large-scale data with specialized retrieval needs.
The choice of architecture depends on the project's complexity, scale, and domain requirements.
For quick and simple solutions, go with Naive RAG;
For moderately complex projects, Advanced RAG offers a balanced approach;
For sophisticated, large-scale systems, Modular RAG provides unparalleled flexibility and performance.
Organizations should evaluate their use cases, resource availability and long-term scalability needs to select the most appropriate RAG architecture.
